
Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Chapter 2 Notes


The steps of a machine learning project:
- Look at the big picture
- Get the data
- Discover and visualize the data to gain insights
- Prepare the data for ML algorithms
- Select a model and train it
- Fine-tune your model
- Present your solution
- Launch, monitor, and maintain your system
Task: California House Price Prediction
Frame the Problem
- Predict house prices
The first question to ask your boss is what exactly is the business objective; building a model is probably not the end goal. How does the company expect to use and benefit from this model? (35)
- i.e. Does the company need dollar estimates or will buckets like low/medium/high work?
The next question to ask is what the current solution looks like (if any). It will often give you a reference performance, as well as insights on how to solve the problem. (36)
- This might be a manual process
Select a Performance Measure
- How much error the system typically makes in its predictions, with a higher weight for large errors
RMSE (Root Mean Squared Error)
- Penalizes values far away from true label a lot more heavily
- Generally used for regression problems
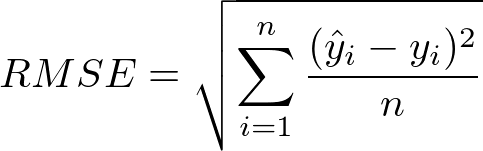
- MAE (Mean Absolute Error) (use for datasets with more outliers)

Get the Data
Data loaded to Pandas DataFrame (housing variable)
housing.head()to inspect first N rows and their attributeshousing.info()for description of data (type, n-rows, n-non-null values)housing.describe()shows summary of numerical attributes (mean, stdev, etc.)housing.hist()-> histogram of each attribute- Look for tail-heavy attributes; will affect model choice Create a test set Do it blind
Your brain is an amazing pattern detection system, which means it is highly prone to overfitting; if you look at the test set, you may stumble upon some seemingly interesting pattern in the test data that leads you to select a particular kind of model. When you estimate the generalization error using the test set, your estimate will be too optimistic and you will launch a system that will not perform as well as expected. This is called data snooping bias. (47)
Stratified sampling: instead of purely random, make sure it represents the true distribution of an important attribute
- i.e. 51.3% male, 48.7% female
Discover and Visualize the Data to Gain Insights
- Do visualizations, etc. on training set only
- corr_matrix =
housing.corr()to get correlations between every attributecorr_matrix['median_house_value'].sort_values(ascending=False)- Only measures linear correlations and can miss out on non-linear correlations
- Play around with combined attributes, i.e.
bedrooms_per_room - This round of exploration does not have to be absolutely thorough; the point is to start off on the right foot and quickly gain insights that will help you get a first reasonably good prototype. (59)
Prepare the data for ML algorithms
Write reusable functions. Why?
- Reproduce on new data in same project
- Build a library to use in future projects
- Use same functions in live systems to ensure consistency
- Try various transformations to see which combination works best
SimpleImputerused to fill in null values- Good idea to use even if no null values in training set, can’t make any guarantees about test set and live data
you should compute the median value on the training set and use it to fill the missing values in the training set. Don’t forget to save the median value that you have computed. You will need it later to replace missing values in the test set when you want to evaluate your system, and also once the system goes live to replace missing values in new data.
Text Attributes
OrdinalEncoder()orpd.factorize()One issue with this representation is that ML algorithms will assume that two nearby values are more similar than two distant values. This may be fine in some cases (e.g., for ordered categories such as “bad,” “average,” “good,” and “excellent”), but it is obviously not the case for the ocean_proximity column (for example, categories 0 and 4 are clearly more similar than categories 0 and 1).
- To fix this problem we use one hot encoding
housing_cat_1hot = sklearn.preprocessing.OneHotEncoder().fit_transform(housing_cat_encoded.reshape(-1, 1))- Need to reshape since fit_transform expects 2D array
- Useful Tip:
If a categorical attribute has a large number of possible categories (e.g., country code, profession, species), then one-hot encoding will result in a large number of input features. This may slow down training and degrade performance. If this happens, you may want to replace the categorical input with useful numerical features related to the categories: for example, you could replace the ocean_proximity feature with the distance to the ocean (similarly, a country code could be replaced with the country’s population and GDP per capita). Alternatively, you could replace each category with a learnable, low-dimensional vector called an embedding. Each category’s representation would be learned during training. This is an example of representation learning (see Chapters 13 and 17 for more details).
Custom Transformers
You want your transformer to work seamlessly with Scikit-Learn functionalities (such as pipelines), and since Scikit-Learn relies on duck typing (not inheritance), all you need is to create a class and implement three methods: fit() (returning self), transform(), and fit_transform(). (65)
- Add
TransformerMixinandBaseEstimatoras base classes to get goodies
from sklearn.base import BaseEstimator, TransformerMixin
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room = True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X, y=None):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household,
bedrooms_per_room]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
The more you automate these data preparation steps, the more combinations you can automatically try out, making it much more likely that you will find a great combination (and saving you a lot of time).
Feature Scaling
All features should be on the same scale. With no feature scaling, room totals range from 6 to 39,320, while median income only rated from 0 to 15. This throws things off
- Min-max scaling
- Scale to 0-1. Bad if there are outliers.
MinMaxScaler
Standardization
- Subtract the mean from all values, divide by variance so that resulting distribution has zero variance
- No specific range, which can negatively affect some models
- Less affected by outliers
StandardScaler
Pipelineis a great abstraction. You can use it to set off sequences of transformationsExposes same methods as final estimator
- Min-max scaling
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attribs_adder', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
housing_num_tr = num_pipeline.fit_transform(housing_num)
ColumnTransformer- More convenient to have a single transformer able to handle all columns
from sklearn.compose import ColumnTransformer
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", OneHotEncoder(), cat_attribs),
])
housing_prepared = full_pipeline.fit_transform(housing)
- Useful Tip:
Instead of using a transformer, you can specify the string "drop" if you want the columns to be dropped, or you can specify "passthrough" if you want the columns to be left untouched. By default, the remaining columns (i.e., the ones that were not listed) will be dropped, but you can set the remainder hyperparameter to any transformer (or to "passthrough") if you want these columns to be handled differently.
Select and Train a Model
- Start with linear regression to establish baseline
-
most districts’ median_housing_values range between $120,000 and $265,000, so a typical prediction error of $68,628 is not very satisfying
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(random_state=42)
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
- The main ways to fix underfitting are to select a more powerful model, to feed the training algorithm with better features, or to reduce the constraints on the model. (70)
- Better evaluation using K-fold cross-validation:
randomly splits the training set into 10 distinct subsets called folds, then it trains and evaluates the Decision Tree model 10 times, picking a different fold for evaluation every time and training on the other 9 folds. The result is an array containing the 10 evaluation scores. (71)
from sklearn.model_selection import cross_val_score scores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring="neg_mean_squared_error", cv=10) tree_rmse_scores = np.sqrt(-scores)Scikit-Learn’s cross-validation features expect a utility function (greater is better) rather than a cost function (lower is better), so the scoring function is actually the opposite of the MSE (i.e., a negative value), which is why the preceding code computes -scores before calculating the square root.
“Possible solutions for overfitting are to simplify the model, constrain it (i.e., regularize it), or get a lot more training data. Before you dive much deeper into Random Forests, however, you should try out many other models from various categories of Machine Learning algorithms (e.g., several Support Vector Machines with different kernels, and possibly a neural network), without spending too much time tweaking the hyperparameters. The goal is to shortlist a few (two to five) promising models.
Fine-tune Your Model
- Model selection and data cleanliness are 95% of performance. Hyperparameter tuning is only the last 5%
- Can use
GridSearchCV(you specify the hyperparameter space to search) orRandomizedSearchCV(for large search spaces) - Once model is fine-tuned, it’s ready for showtime
Launch, Monitor, and Maintain Your System
- Considerations:
- Monitoring
- Sample predictions and verify (most of the time with human help)
- Pipeline to retrieve fresh data
- Deploy with SciKit
joblib - Can deploy separate data prep pipeline and actual prediction pipeline
import joblib
joblib.dump(my_model, "my_model.pkl")
my_model_loaded = joblib.load("my_model.pkl")